
TL;DR:
- A cybersecurity knowledge base is a structured, centralized repository that supports detection, response, and compliance by storing threat data, policies, and playbooks. It functions as the operational memory of a security program, connecting intelligence to practical actions and enabling AI integration. Maintaining it as a dynamic, queryable system with automated updates and structured formats enhances incident response and security outcomes.
A cyber security knowledge base is defined as a curated, structured repository that centralizes security intelligence, policies, playbooks, and threat data to support detection, response, and compliance operations. Without one, security teams operate from fragmented documentation, outdated wikis, and tribal knowledge that disappears when people leave. The most effective programs treat this repository not as a filing cabinet but as a living operational layer that both human analysts and AI agents query in real time. Sources like MITRE ATT&CK, CISA KEV, and Sigma rules form the raw material. What you build on top of them determines how fast your team responds when it matters.
What is a cyber security knowledge base and why does it matter?
A security knowledge base is the operational memory of your security program. It stores the context your team needs to act, not just the documents they might read someday. The distinction matters because most organizations already have documentation. What they lack is structured, queryable intelligence that connects a CVE to an affected asset, a detection rule to an incident playbook, and a compliance control to the evidence that satisfies it.

The D3One Product Security project defines true knowledge bases as active context layers queryable by human analysts and AI agents alike. That framing shifts the goal from "store everything" to "make everything findable and usable." A security team that can query its knowledge base mid-incident recovers faster than one that searches through SharePoint folders.
MITRE ATT&CK is the most widely cited example of this model in practice. It maps adversary techniques to detection opportunities and mitigation controls in a structured, machine-readable format. CISA KEV (Known Exploited Vulnerabilities) adds urgency signals. Sigma rules provide detection logic that translates across SIEM platforms. A mature security knowledge repository pulls from all three and layers in your internal context.
How do modern security knowledge bases aggregate intelligence?
Data aggregation is where most knowledge base projects fail or succeed. The volume of public threat and vulnerability data is large enough that pulling everything creates noise. The skill is selective ingestion.
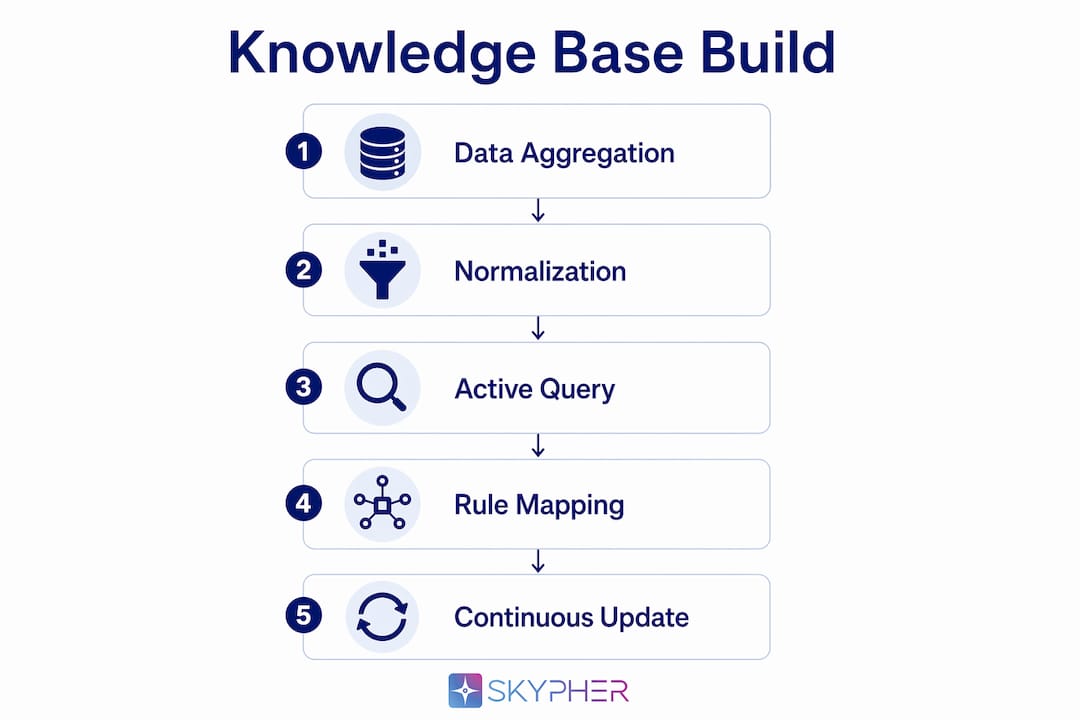
As of early 2026, leading vulnerability databases aggregate data from 25–38+ public sources, normalizing records across more than 25,000 applications. That scale means no single team can manually curate everything. Automation is not optional.
The most effective architectures use a three-tier model:
- Tier 1 (Canonical feeds): Raw, authoritative sources like NVD, GCVE, and MITRE ATT&CK. These are ingested automatically and treated as ground truth.
- Tier 2 (Curated operational knowledge): Normalized, enriched records that map vulnerabilities to your environment, detection rules, and response procedures.
- Tier 3 (Internal playbooks): Organization-specific runbooks, asset inventories, and historical incident data that give context no public feed can provide.
Data formats matter as much as data sources. STIX (Structured Threat Information Expression) and JSON are the standard machine-readable formats for threat intelligence sharing. If your knowledge base stores data in PDFs or unstructured text, AI agents cannot query it effectively and human analysts waste time reformatting before they can act.
The open-source project PatchCurated demonstrates this architecture well. It aggregates patch metadata from 38+ sources into a portable SQLite database covering 25,000+ applications. The SQLite format gives teams offline access and full control without vendor lock-in. That portability is a feature, not an afterthought.
Pro Tip: When building your ingestion layer, avoid wholesale mirroring of external feeds. Selective ingestion reduces noise and increases the trustworthiness of your Tier 1 data, which is the foundation everything else depends on.
Static libraries vs. dynamic knowledge systems: which do you need?
Not all security knowledge repositories are equal. The differences between a static document library and a dynamic, queryable knowledge system are significant enough to affect incident response times and compliance audit outcomes.
| Feature | Static Document Library | Dynamic Knowledge System |
|---|---|---|
| Update method | Manual, periodic | Automated, continuous |
| Query capability | Keyword search only | Structured queries, AI-ready |
| Integration | Standalone | Connects to SIEM, SOAR, ticketing |
| Offline access | Yes, but stale | Portable formats (SQLite) support both |
| Vendor dependency | Often vendor-locked | Community or vendor-neutral options |
| AI compatibility | Low | High (STIX, JSON, vector-ready) |
Static libraries have their place. Comprehensive security resource collections organize 160+ curated assets across 9+ specialized categories, covering threat intelligence, cryptography, and incident response. For training and onboarding, that depth is genuinely useful. The problem is that a PDF checklist cannot tell you whether a newly published CVE affects your production environment.
Dynamic systems solve the currency problem. They pull from trusted feeds on a schedule, normalize the data, and surface it through interfaces that analysts and automated tools can query. The HODOR project (an AI-ready defensive knowledge base) is a practical example of this model. It uses tiered knowledge layers with structured machine-readable formats so that AI agents can multiply analyst capacity rather than replace it.
Vendor-neutral, community-maintained systems have a specific advantage: they surface blind spots that vendor-locked solutions miss. A vendor has commercial incentives to emphasize certain threats and downplay others. Open-source community data does not carry that bias.
What are the practical applications of a security knowledge base?
A well-built security knowledge base changes daily operations in four concrete ways.
1. Detection rule management. Sigma rules stored in your knowledge base can be mapped to MITRE ATT&CK techniques, tested against historical log data, and deployed to your SIEM with version control. Without a knowledge base, detection rules live in individual analyst laptops or undocumented SIEM configurations.
2. Incident response playbooks. A security incident response guide embedded in your knowledge base connects each alert type to a specific response procedure. Analysts stop improvising and start executing. Response times drop because the decision tree is already built.
3. Compliance control mapping. Controls from ISO 27001, SOC 2, and NIST CSF can be mapped to your existing policies and evidence artifacts inside the knowledge base. When an auditor asks for evidence, you query rather than scramble. Building a strong information security checklist within your knowledge base is one of the fastest ways to operationalize compliance requirements.
4. AI and human analyst collaboration. The HODOR architecture demonstrates that AI agents and human analysts querying the same structured data context produce better outcomes than either working alone. AI handles volume. Humans handle judgment. The knowledge base is the shared context that makes both effective.
Embedding your knowledge base into the software development lifecycle (SDLC) extends these benefits upstream. Security requirements, threat models, and approved libraries stored in the knowledge base give developers the context to make secure decisions without waiting for a security review. The D3One guidance on embedding knowledge bases within SDLC workflows makes this case clearly. Security teams that operationalize defenses through integrated tooling outperform those that maintain separate documentation portals.
Pro Tip: Practitioners consistently prioritize downloadable, practical content like checklists and templates over reference documents. Build your knowledge base to surface these assets first, not last.
How do you maintain a knowledge base that stays useful?
The most common failure mode for a security knowledge base is treating it as a project with a completion date. It is not. It is a system that requires ongoing maintenance or it becomes a liability.
Auto-updating sync engines that aggregate data from dozens of sources on a regular schedule are the foundation of a current knowledge base. PatchCurated's maintenance model shows how automated ingestion keeps patch intelligence current without manual intervention. Manual curation cannot keep pace with the volume of new CVEs, threat actor TTPs, and detection rules published weekly.
The key maintenance practices that separate effective knowledge bases from stale ones:
- Automate ingestion from Tier 1 feeds on at least a daily schedule. Weekly is too slow for active threat environments.
- Audit Tier 2 and Tier 3 content quarterly. Playbooks go stale when your environment changes. A runbook written for an on-premises environment does not apply to a cloud-native one.
- Use portable formats. SQLite databases and JSON files give you full control and offline access. Proprietary formats create vendor dependency that limits your options later.
- Embed the knowledge base in daily tooling. If analysts have to open a separate portal to access it, they will not use it consistently. Integration with Slack, ServiceNow, or your SIEM makes access frictionless.
- Track usage. If certain sections are never queried, they are either irrelevant or inaccessible. Both are problems worth fixing.
Adapting to evolving compliance and threat requirements is easier when your knowledge base is already structured to absorb new data. Teams that build for adaptability spend less time rebuilding when the threat landscape shifts.
Key takeaways
A cyber security knowledge base works only when it is treated as a living, queryable system rather than a static document archive.
| Point | Details |
|---|---|
| Define it as a context layer | A knowledge base is operational infrastructure, not a document library. |
| Use a three-tier architecture | Separate canonical feeds, curated intelligence, and internal playbooks for clarity and control. |
| Prioritize machine-readable formats | STIX and JSON formats make your knowledge base queryable by both analysts and AI agents. |
| Automate ingestion | Manual updates cannot keep pace with daily CVE and threat intelligence volume. |
| Embed it in daily workflows | Knowledge bases accessed through existing tools get used. Separate portals get ignored. |
The shift i keep seeing teams miss
Most security teams I have worked with build their first knowledge base the wrong way. They start with a Confluence space or a SharePoint site, dump their policies into it, and call it done. Six months later, it is out of date and nobody trusts it.
The shift that actually changes outcomes is architectural. When you move from a document store to a structured, queryable system, the knowledge base stops being something you maintain and starts being something you use. That is a meaningful difference. Analysts who can query their knowledge base during an incident make better decisions. AI tools that have access to structured internal context generate better outputs. The AI advantages in security workflows only materialize when the underlying data is structured well enough for AI to use.
The other thing I advocate for strongly is vendor neutrality. I have seen organizations build their entire knowledge base inside a vendor platform, then face a painful migration when the vendor changes pricing or discontinues a feature. Open-source projects like PatchCurated and HODOR exist precisely to give teams control over their own intelligence infrastructure. That control is worth the additional setup effort.
The hardest part is cultural, not technical. Getting analysts to contribute to and trust the knowledge base requires that it actually helps them do their jobs faster. Start with the content that gets used most: incident response playbooks, detection rules, and compliance control mappings. Build credibility there first, then expand.
— Gaspard
How Skypher strengthens your security knowledge operations
Security questionnaire responses are one of the most knowledge-intensive tasks your team handles. Every answer draws on policies, controls, and compliance evidence stored across your organization. Skypher's Smart Security Knowledge Base centralizes that content into a structured, AI-queryable repository that your team can actually use at speed.
Skypher's questionnaire automation platform connects to over 40 third-party risk management platforms, integrates with Slack, ServiceNow, Confluence, and SharePoint, and can answer 200 questions in under one minute using your own verified security knowledge. For security leaders who want their knowledge base to do real work rather than sit in a portal, Skypher is built for exactly that.
FAQ
What is a cyber security knowledge base?
A cyber security knowledge base is a structured, centralized repository of security intelligence, policies, playbooks, and threat data that security teams query to support detection, response, and compliance operations. It functions as the operational memory of a security program.
How is a security knowledge base different from a document library?
A document library stores files for reference. A security knowledge base is queryable, auto-updated, and integrated into security workflows so analysts and AI agents can retrieve structured intelligence during active operations.
What data sources should a security knowledge base include?
Effective knowledge bases pull from authoritative public sources like MITRE ATT&CK, NVD, CISA KEV, and GCVE, then layer in internal playbooks, asset inventories, and detection rules. Aggregating from 25–38+ sources is the current standard for comprehensive coverage.
How often should a security knowledge base be updated?
Tier 1 canonical feeds should update at least daily. Internal playbooks and curated intelligence should be audited quarterly to remove stale content and reflect changes in your environment.
What formats make a knowledge base ai-ready?
STIX and JSON are the standard machine-readable formats for threat intelligence. Storing knowledge base content in these formats allows AI agents to query and process data directly, rather than requiring human reformatting before use.